Mixed-Precision Communication-Avoiding SGD for Generalized Linear Models on GPUs
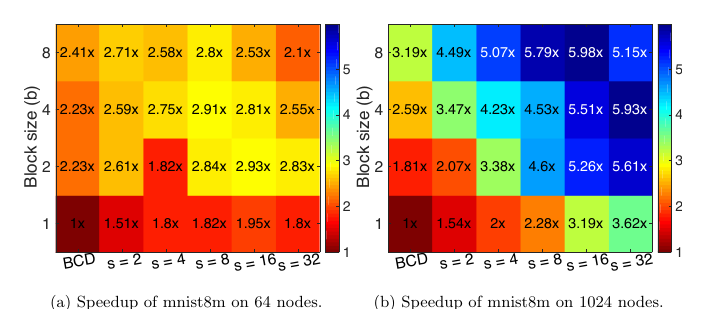
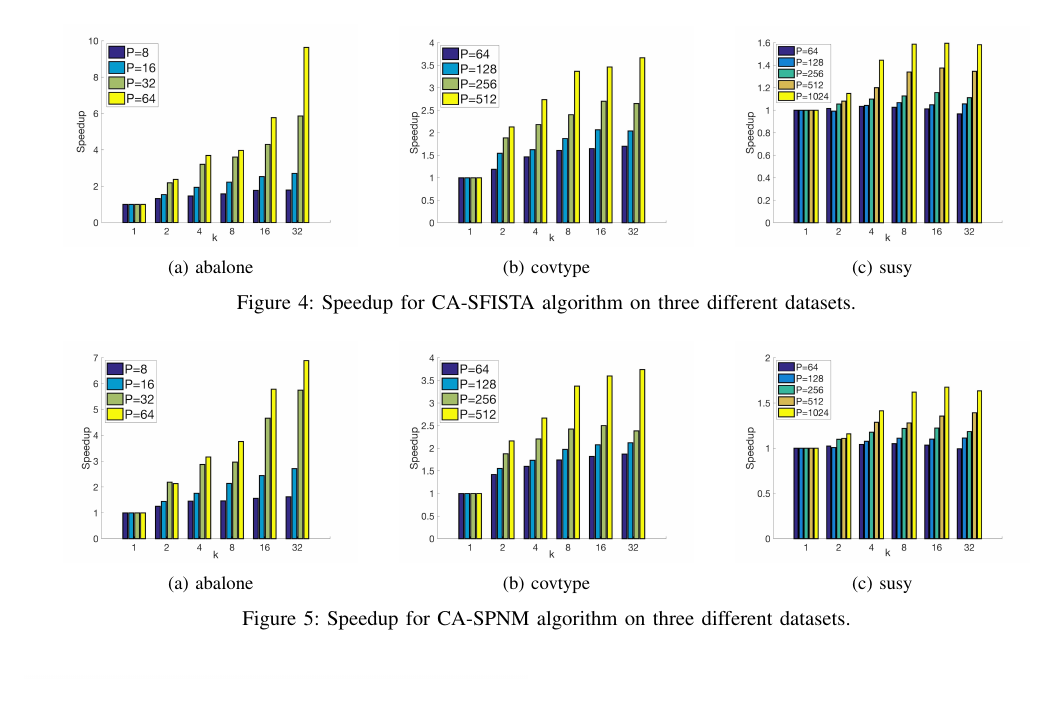
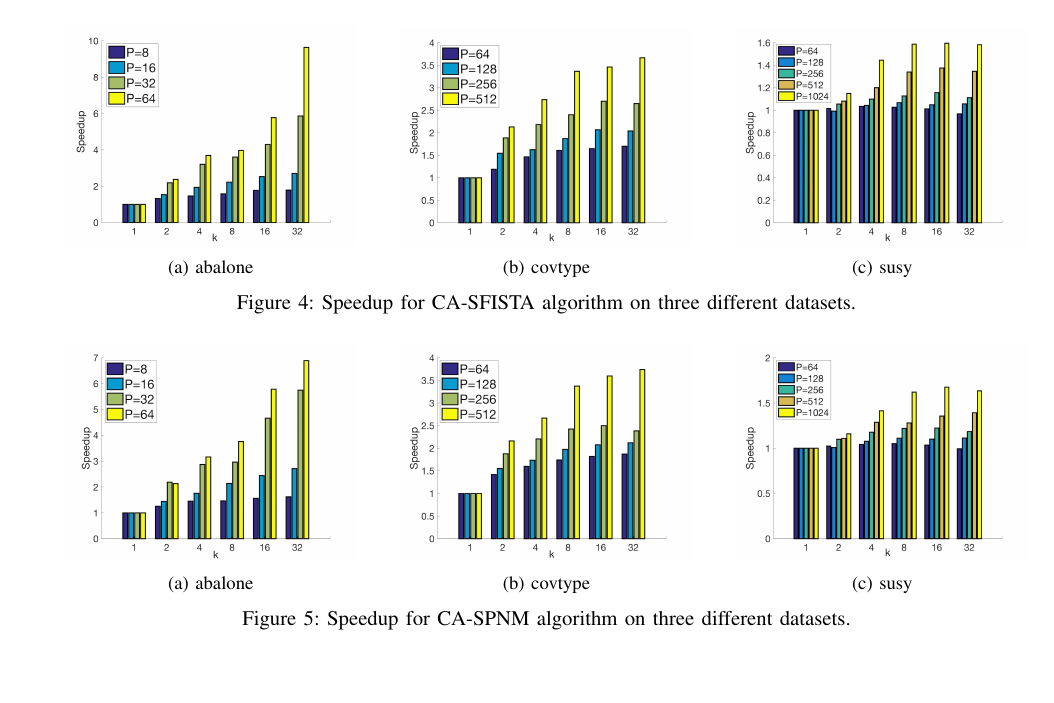
Distributed SGD is limited by communication rather than computation, since each iteration requires an AllReduce across processes. We study mixed-precision communication-avoiding SGD (CA-SGD) for generalized linear models on NVIDIA GPUs, decomposing the local rounding error of one CA-SGD outer iteration into nine independent precision choices that depend on the hardware only through its low-precision unit roundoffs. On NERSC Perlmutter A100 GPUs, mixed-precision CA-SGD matches FP32 SGD loss within 0.5% and reaches 5.1-6.8x speedup over FP32 SGD on the epsilon, SUSY, HIGGS, synth, and Poisson-synth datasets.