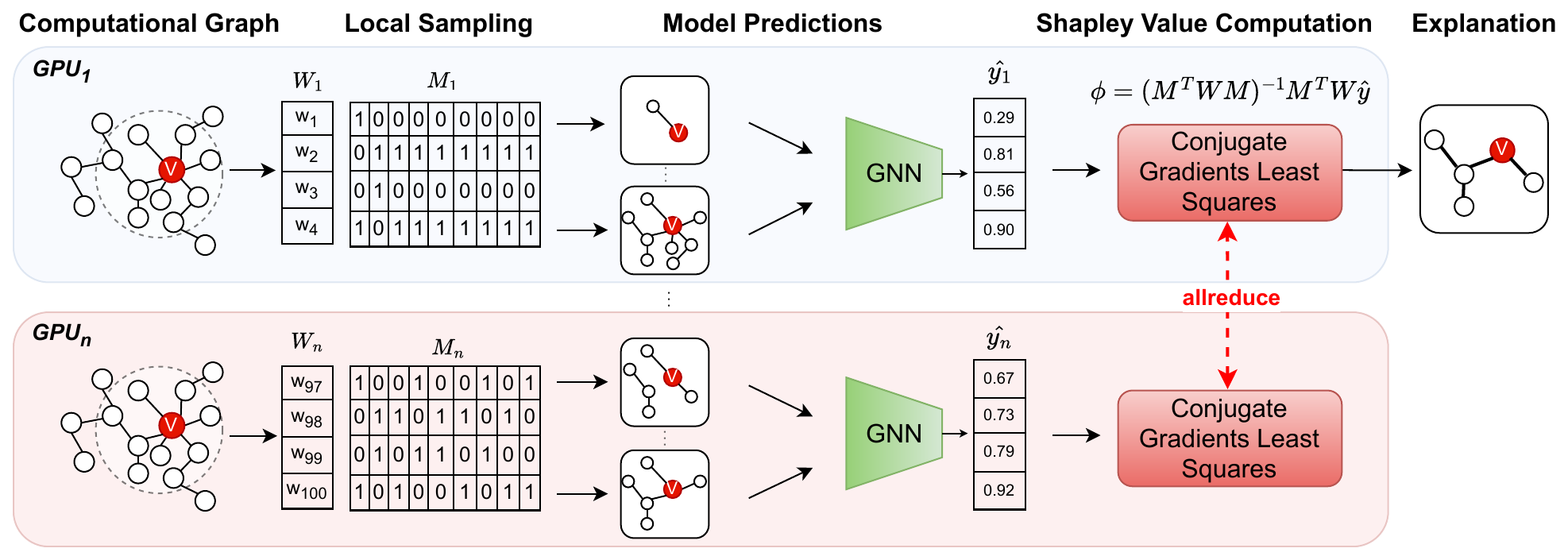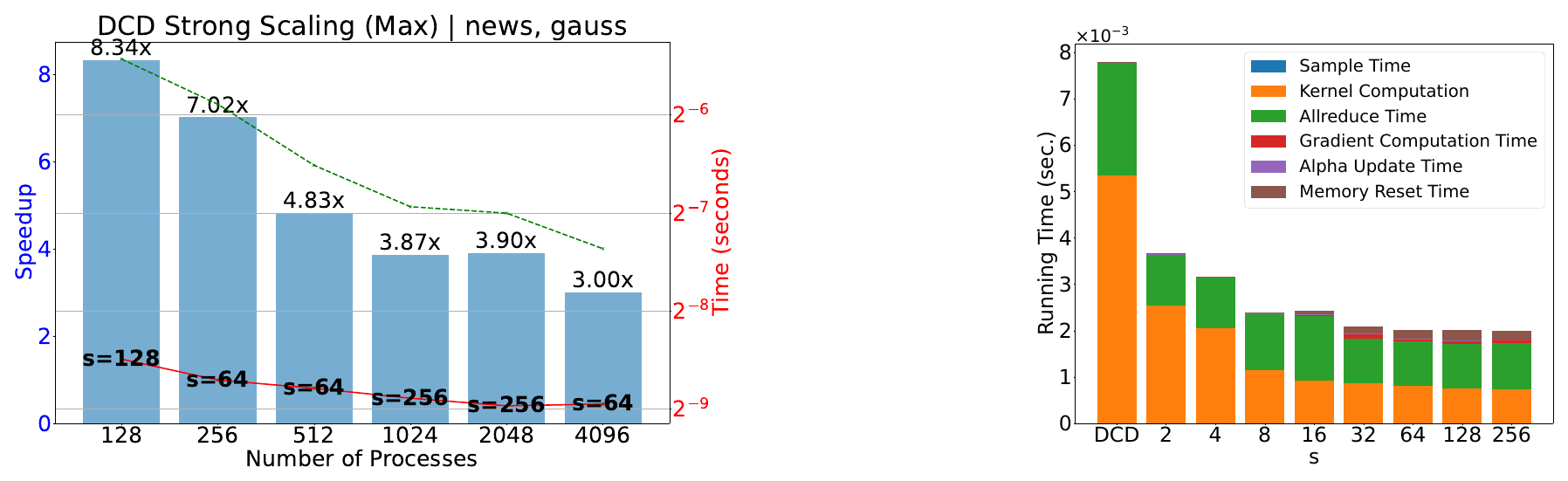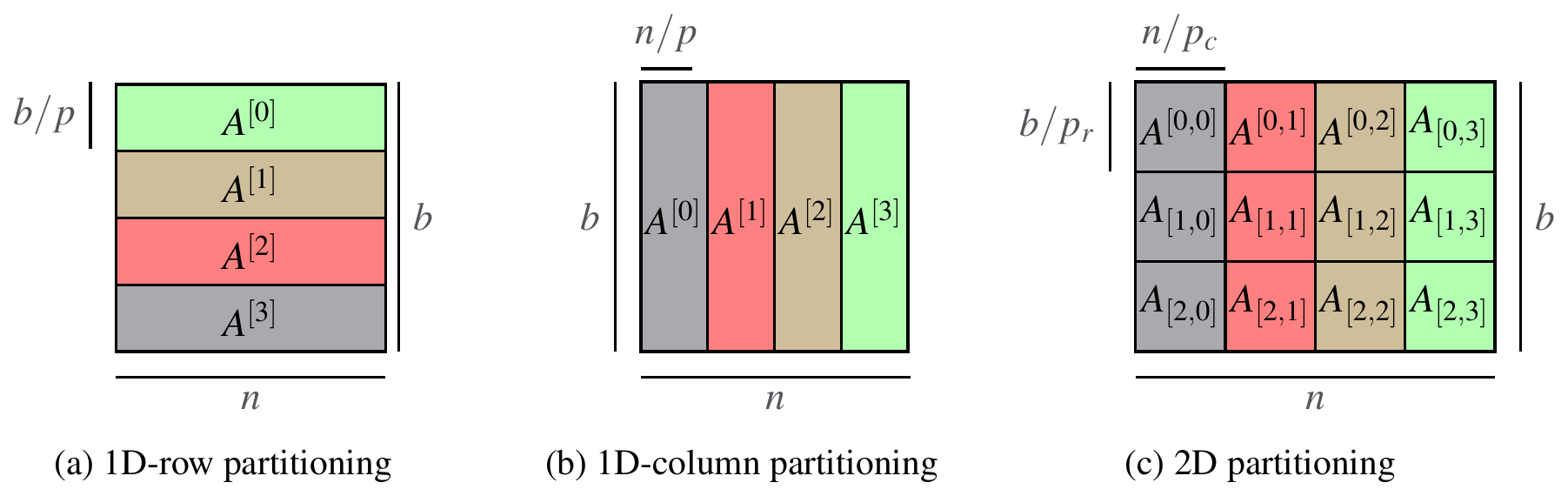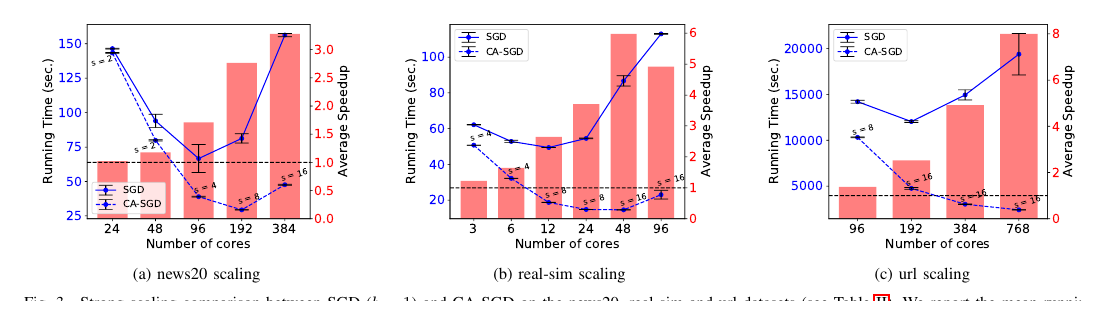
Parallel Rank-Adaptive Higher Order Orthogonal Iteration
Higher Order Orthogonal Iteration (HOOI) is an iterative algorithm that computes a Tucker decomposition of an input tensor. We present distributed-memory parallel, rank-adaptive variants of HOOI that adaptively determine the core tensor ranks rather than requiring them as fixed inputs, using efficient parallel tensor-times-matrix (TTM) and SVD kernels to scale Tucker decomposition to large tensors.