Avoiding Communication in Logistic Regression
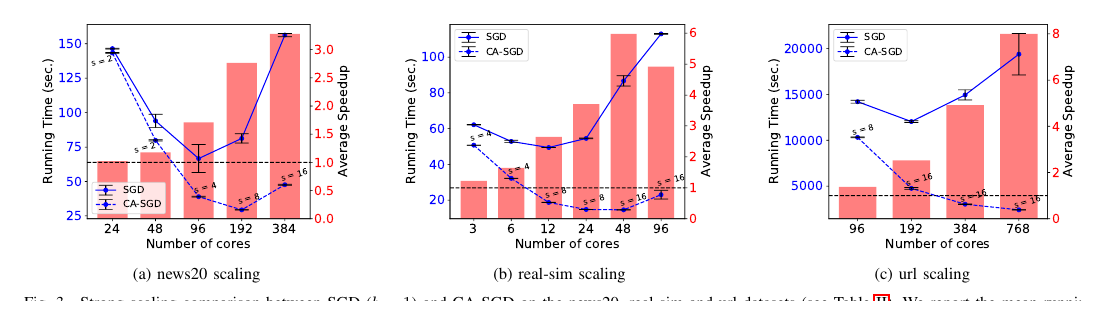
This work introduces Communication-Avoiding SGD (CA-SGD) for distributed-memory logistic regression. CA-SGD reorganizes stochastic gradient computations to communicate every $s$ iterations instead of every iteration and achieves speedups of up to 4.97x over SGD on a high-performance InfiniBand cluster without altering convergence behavior or accuracy.