Reducing Communication in Proximal Newton Methods for Sparse Least Squares Problems
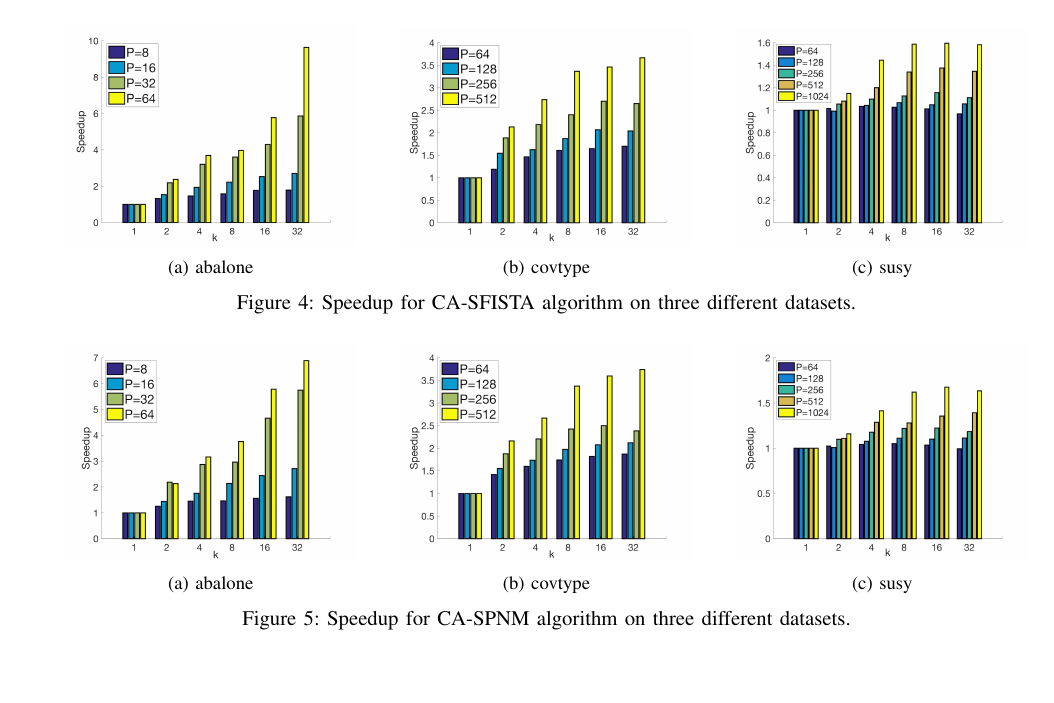
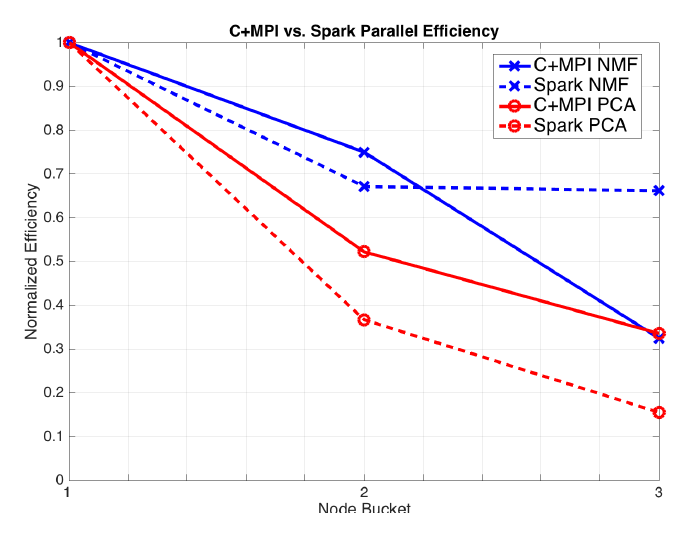
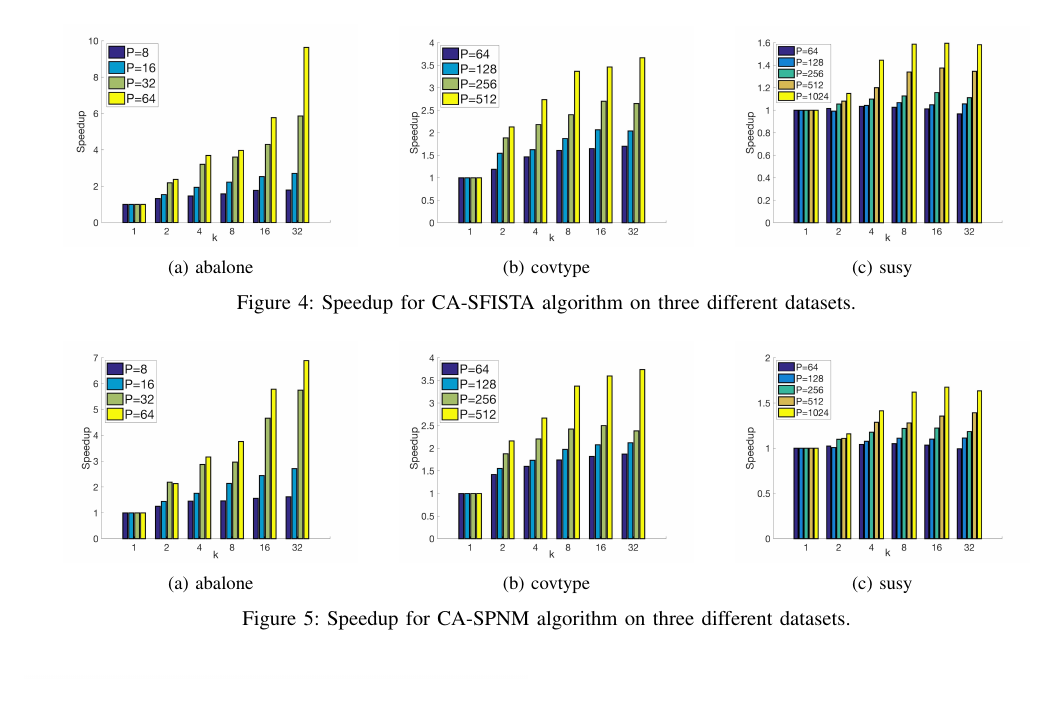
This work proposes RC-SFISTA with iteration-overlapping and Hessian reuse for sparse least-squares problems. The method reduces latency costs by a factor of $k$ and demonstrates speedups up to 12x compared to ProxCoCoA on MPI and Spark implementations evaluated on 1 to 512 nodes.