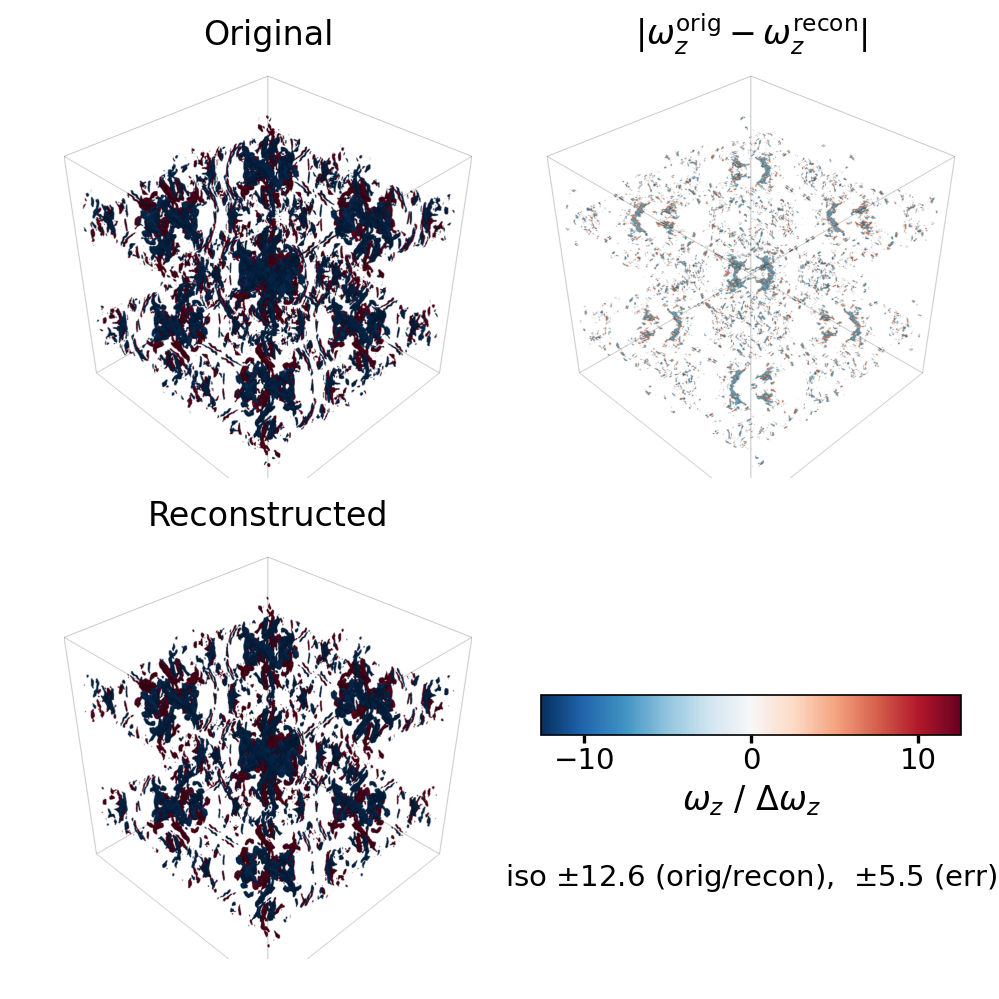
High-Performance Star-M SVD for Big Data Compression
Tensor-based decomposition methods compress large datasets with less accuracy loss than traditional matrix methods. Under the star-M tensor framework, tensors decompose in a matrix-mimetic way through the star-M SVD, which carries optimality guarantees but has been confined to productivity-oriented language implementations. We present a shared-memory parallel, high-performance implementation built on batched tensor-times-matrix and slice-wise SVD kernels, achieving a 42x strong-scaling speedup from 1 to 64 threads on the ncep-air-6 dataset.